
DS228:階層クラスター分析と非階層クラスター分析の違いを説明できる
クラスター分析とは、データを類似性に基づいてグループ化する手法です。階層クラスター分析とk-meansクラスタリングは、代表的な2つの手法であり、データの性質や解析の目的によって使い分けが必要です。それでは、それぞれの特徴を見ていきましょう。
階層クラスター分析の概要と利点・欠点
階層クラスター分析とは?
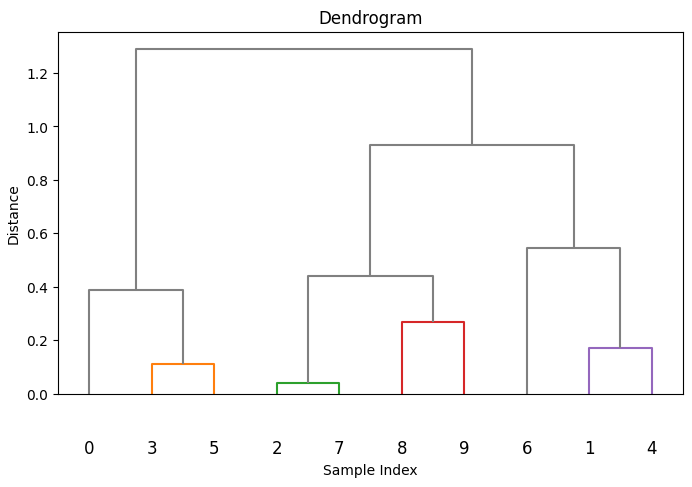
階層クラスター分析は、データを階層構造でグループ化する手法です。「凝集型」は全てのデータポイントを個別のクラスターから始め、次第に統合していく方法です。「分割型」は逆に、全データを一つのクラスターと見なし、分割していきます。最終的な結果はデンドログラムと呼ばれる図で表され、データの階層的な関係が視覚的に理解できます。
デンドログラムの見方
デンドログラムでは、縦軸がクラスター間の距離を示しており、横軸にデータポイントが並びます。距離が近いほどデータが似ていることを表し、視覚的にどのデータがどの段階でグループ化されたかを確認することができます。例えば、マーケティングの顧客セグメントを階層的に分析する際に活用されます。
利点
-
クラスター数を事前に設定しなくても良いため、探索的な分析に適しています。
-
デンドログラムで視覚的に理解しやすく、データの全体像を把握しやすい。
欠点
-
大規模データには不向きです。具体的には、数万件以上のデータセットだと計算コストが急激に増加します。
-
初期設定や距離の定義に依存するため、結果が変わりやすいというリスクがあります。
k-meansクラスタリングの概要と利点・欠点
k-meansクラスタリングとは?
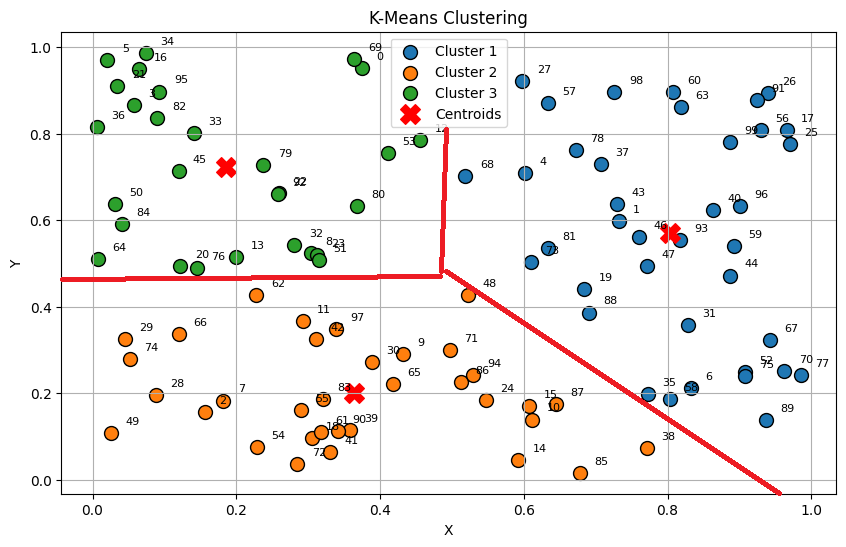
k-meansクラスタリングは、あらかじめクラスター数(k)を指定し、その数に基づいてデータをグループ化する手法です。初期のクラスター中心をランダムに設定し、データの再割り当てと中心の再計算を繰り返して、最適なクラスターを見つけます。
この手法は、大規模データにも対応可能で、例えばEコマースのデータ分析やソーシャルメディアのユーザセグメント分析でよく利用されます。
利点
- 計算コストが低いため、数十万件以上の大規模データセットに適しています。
- 明確なクラスター数を設定でき、解析がスムーズです。
欠点
- クラスター数を事前に設定する必要があるため、探索的な分析には不向きです。
- 球状のクラスターに限定され、データが複雑な形状を持つ場合には適用しにくいことがあります。
- 異常値(アウトライア)に敏感で、極端なデータが結果に影響を与えることがあります。
手法の選び方:実際の使用例とポイント
手法を選ぶ際には、以下のポイントを考慮することが重要です:
-
データの規模:小規模データやクラスター数が未知の場合は、階層クラスター分析が適しています。一方、数万件以上のデータを迅速に分析したい場合は、k-meansが有効です。
-
分析の目的:階層クラスター分析は探索的分析に向いており、データの階層構造や隠れたパターンを見つけるのに役立ちます。一方、k-meansは、すでに目的が定まっている場合や明確なグループ分けが必要な場面で効果的です。
-
クラスター数の事前知識:クラスター数が未知の場合は、階層クラスター分析を使い、探索的にクラスターの構造を理解しましょう。クラスター数が分かっている場合や、大規模データを処理したい場合にはk-meansを選ぶのが適切です。
まとめ
階層クラスター分析とk-meansクラスタリングは、それぞれ異なる強みと弱みを持っています。データの規模や目的に応じて最適な手法を選択し、効率的にデータの洞察を得ることが重要です。クラスター数が不明な場合は階層クラスター分析を、大規模データでクラスター数が明確な場合はk-meansを選択することが基本的なアプローチです。データサイエンティスト検定DS228のスキルに対応した知識として、これらのポイントを理解し、実践に活用してください。
![]()
![]()


コメント