
DE057:正規化手法(第一正規化~第三正規化)を用いてテーブルを正規化できる
データベース設計に悩んでいる方は、次のような問題を抱えていませんか?
- テーブル設計が複雑で、どこにどのデータを格納すべきかわからない
- データが重複していて、更新や管理が煩雑になっている
- データの整合性が取れず、エラーが頻発している
こうした課題原因の多くは、データベースの正規化が不十分であることに起因します。本記事では、正規化を行うことで、冗長なデータを削減し、データの整合性を向上させる方法を具体的に解説します。特に第一正規化(1NF)から第三正規化(3NF)までの手法を詳しく説明し、実際にどのようにテーブルを最適化できるかを理解できるようになります。
正規化とは?
正規化とは、データベース内の冗長なデータを排除し、データの一貫性を保ちながら最適な構造を作る技法です。正規化によって、データの管理が効率化され、データベースの保守が容易になります。以下では、第一正規化から第三正規化までのステップを説明し、それぞれの具体例と解決策を示します。
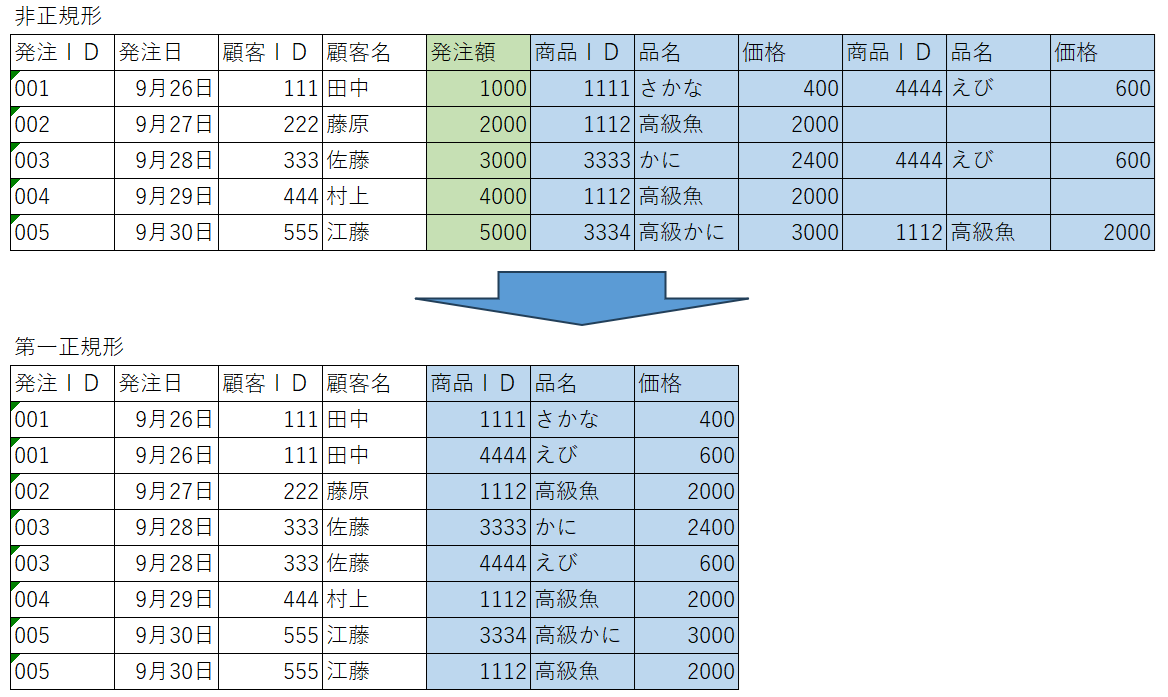
第一正規化(1NF):データの一意性を確保する
第一正規化では、各フィールドに単一の値しか含まないようにする必要があります。
例えば、1つのフィールドに複数の商品情報を格納することは第一正規化に違反します。そこで、商品情報を一意の発注IDに関連付けます。これにより、複数の商品情報を適切に管理できます。
下図の例では大きく分けて2つの処理を行っています。
- 計算で求める事の出来る「発注額」の除去
- 重複した「商品ID」「品名」「価格」を統合
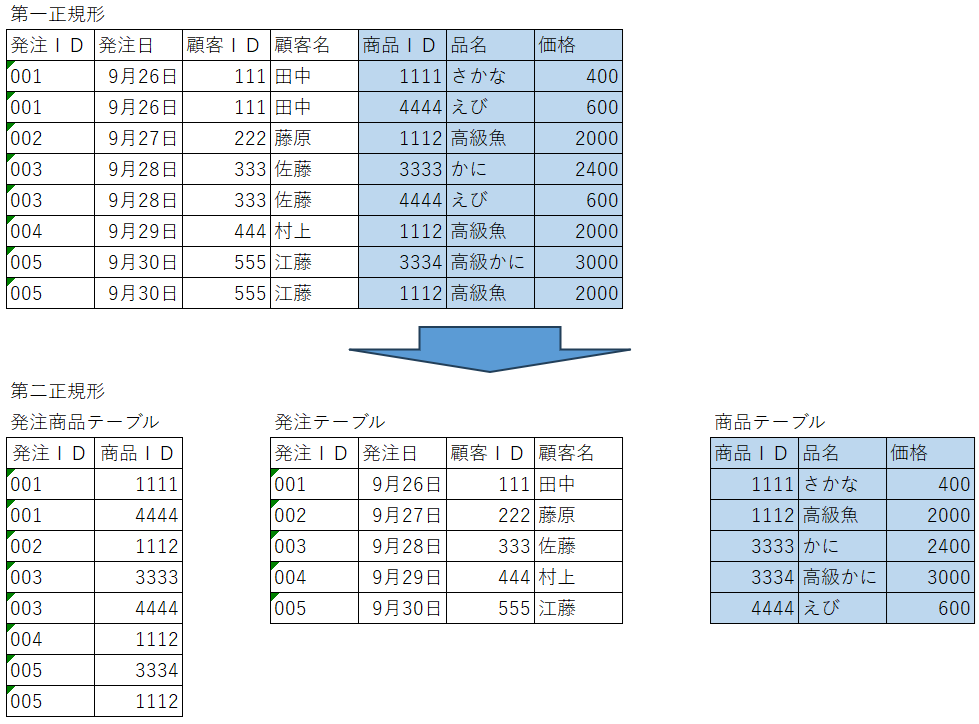
第二正規化(2NF):部分依存の解消
第二正規化は、テーブルが第一正規化を満たしている状態で、部分関数従属(主キーの一部に依存する列)を排除することを目的としています。下図の例では「発注ID」に従属する情報と「商品ID」に従属する情報があるのでこれらを分離する事が第二正規化の操作となります。
具体的には以下の3つのテーブルに分ける処理を行います。
- 「発注ID」に従属する「発注日」「顧客ID」「顧客名」のテーブルを作成する。
- 「商品ID」に従属する「品名」と「価格」のテーブルを作成する。
- 上記2つのテーブルを紐づける「発注商品テーブル」を作成する。
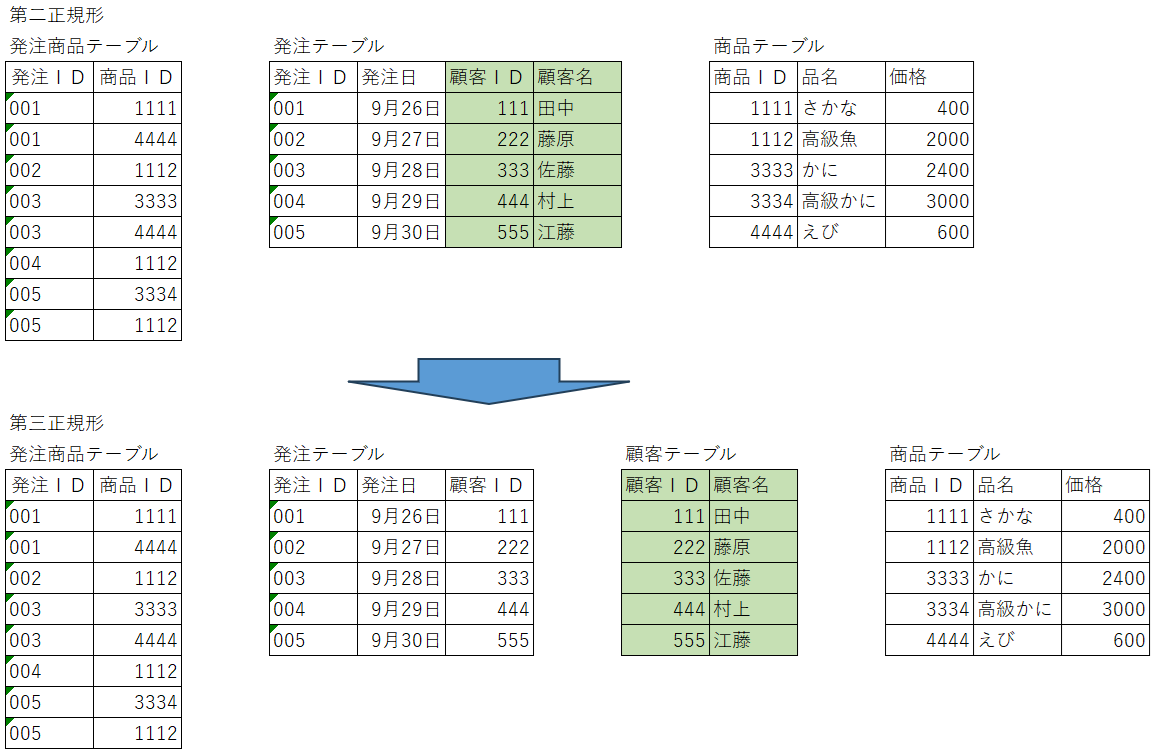
第三正規化(3NF):推移的従属の排除
第三正規化では、非キー属性が他の非キー属性に依存している状態(推移的従属)を排除します。これにより、データの更新や削除時に発生する問題を防ぎます。下図の例では発注テーブルの中に主キーではなく非主キーである「顧客ID」に顧客名が従属しています。これは推移従属関係と呼び、第三正規形を行う事で別のテーブルに分割します。
正規化の利点と注意点
正規化により、データベースは次のような利点を得られます。
- データの一貫性が向上し、冗長性が減少する
- 管理が容易になり、大規模データベースにおいても有効
ただし、過度に正規化を進めると、クエリのパフォーマンスが低下する場合があります。正規化と非正規化のバランスが重要です。
まとめ
正規化は、データベース設計における基本手法であり、データの冗長性を最小限に抑えることで管理効率を向上させます。第一正規化から第三正規化までのステップを理解し、適切に適用することで、「データの一貫性の向上」や「管理の簡素化」、「信頼性とパフォーマンスの向上などのメリットがあります。ただし、過度の正規化はクエリのパフォーマンス低下を招く可能性があるため、正規化と非正規化のバランスが重要です。正規化のプロセスを理解し実践することで、効率的なデータベース設計が実現できます。
データサイエンティスト検定DE057のスキルに対応した知識として、これらのポイントを理解し、実践に活用してください。
![]()
![]()


コメント